
I am in the constant pursuit of knowledge. The desire that resonates deep within my soul and every breath is to make this world better through Informatics and Bioinformatics. To be a part of the story of hope and perseverance for the child who fights a debilitating disease. For the parents who can see that child through all of life's milestones, from graduating to walking down the aisle.
This blog post embarks on a journey to explore six critical domains: Biology, Genetics, Diseases, and Whole Human Genome Sequencing using Oxford Nanopore MinION, AWS HealthOmics, and AWS Bedrock. The goal is to shed light on how these distinct areas can be intertwined to create a holistic understanding of an individual's health, setting the stage for more precise and personalized treatment options.
The discussion then transitions towards Multi-Omics and Multi-Modal data, essential elements for crafting the most potent treatment methodology for cancer patients. This intricate process comprises several stages: Data Collection, Integration, Analysis, Treatment Modeling, Model Evaluation, and Treatment Selection. The ultimate objective is to integrate these model predictions into real-world clinical practice, aiding oncologists in selecting the most beneficial cancer treatment strategies tailored to each patient's distinctive needs.
Furthermore, the blog post highlights the revolutionary influence of AWS Bedrock and AWS HealthOmics data in the medical sector, especially in diagnosing and treating diseases. In pediatric cancer, these advanced technologies contribute to developing a precision treatment plan that aligns with the patient's specific cancer type and genetic blueprint. Regarding autoimmune diseases, the inherent complexities are simplified through genomic sequencing, Machine Learning models, and extensive health databases. This combination accelerates the diagnostic process, facilitating quicker and more accurate diagnoses, and propels the advancement of personalized medicine.
Serving as a comprehensive overview, this blog post aims to bring these diverse components together, presenting a unified approach to Precision Medicine Therapies. I encourage you to reach out with any comments, questions, or requests for additional content.
Main Sections
Section 1 - Biology Overview
Section 2 - Unlocking the Secrets of the Human Genome
Section 3 - Disease and Autoimmune Overview
Section 4 - Oxford Nanopore MinION Whole Human Genome Sequencing
Section 5 - Human Genome Sequencing Data with AWS HealthOmics
Section 6 - Use Cases and Resources for AWS Bedrock in Healthcare
Section 7 - Final Thoughts
Section 1 - Biology Overview
The journey of understanding the human genome and its relationship with diseases begins with a fundamental understanding of biology. This includes the study of life and living organisms, the cellular structures that make them up, and the intricate processes that sustain life. At the core, we are composed of cells, which house our DNA - the blueprint of life. Every characteristic, function, and behavior of all living organisms is, in one way or another, a manifestation of the complex interaction between DNA, RNA, and proteins. Setting this biological stage provides the foundation to delve deeper into the fascinating world of the human genome, diseases, and the transformative potential of bioinformatics.
Genes, DNA, Chromosomes, Cells, Tissue, and Beyond
Genes are the basic building blocks of inheritance. They are found in all living things and affect how they look. Genes comprise DNA (Deoxyribonucleic Acid), a molecule that carries genetic information. DNA is in the nucleus of a cell. It comprises four different chemical bases that are put together in specific patterns called genes.
Chromosomes are long strands of deoxyribonucleic acid and proteins that form tightly packaged structures inside a cell’s nucleus. A chromosome comprises two sister chromatids joined at a single point known as the centromere. Chromosomes contain the genetic information essential for life, including our physical traits and characteristics.
Cells are the basic units of life, existing in both plants and animals. Cells come in many shapes and sizes, but all contain a nucleus (which contains DNA) surrounded by cytoplasm, which holds other essential organelles that help the cell function.
Tissue is a cluster of cells with similar structures and functions grouped to form organs. Four major tissue types (to name a few) are epithelial, connective, muscle, and nervous. An extracellular matrix is a substance that holds cells together, which is what makes up connective tissues.
These basic building blocks make up the complex systems of humans and other organisms, allowing us to understand how they work and interact with each other. With this information, we can start to develop medical treatments that use what we know about biology.

Genes, DNA, Chromosomes, Cells, Tissue, and Beyond Illustration (Copyright: Adam Jones)
Human Cell Anatomy
The anatomy of the human cell is complex and essential for understanding how the body works. The cell's DNA is in the cytoplasm, which surrounds the nucleus and comprises organelles like the mitochondria, endoplasmic reticulum, golgi apparatus, and lysosomes.
The nucleus controls the cell's activities by directing it to make proteins needed for growth and development. It also stores crucial genetic information, like the coding sequences that tell cells how to talk to each other.
The cytoplasm houses various structures called organelles, which perform specialized cellular functions. For example, the mitochondria give cells the energy they need to do their jobs, the endoplasmic reticulum helps make proteins, and the golgi apparatus packs materials to be sent out of the cell. Also, lysosomes break down waste products in the cell and give the cell nutrients.

Human Cell Anatomy Illustration (Copyright: Adam Jones)
Mitochondria
Within the human cell, there is a power plant. Mitochondria are tiny organelles found in the cytoplasm of eukaryotic cells that generate energy for the cell to use. This energy is produced through the process of cellular respiration, which uses glucose from food molecules and oxygen from the air to produce ATP (Adenosine Triphosphate).
Mitochondria play a vital role in creating energy for our cells and keeping inflammation in check. Particular lifestyle and dietary changes can help keep mitochondria in peak operating performance and reduce inflammation within the body. Eating nutrient-dense foods rich in antioxidants, exercising regularly, and getting enough sleep can all help improve mitochondrial health. Additionally, supplementation with CoEnzyme Q10 or other antioxidants may also be beneficial.

Mitochondria Illustration (Copyright: Adam Jones)
Human Body Cell Types
Humans are composed of trillions of cells that come in many shapes and sizes. As mentioned before, four major tissue types of cells are found in the human body (to name a few): epithelial, connective, muscle, and nervous. In the diagram, we have expanded the additional types of human body cell types to provide further examples.
Epithelial cells form a protective barrier between organs, tissues, and other body parts. Connective tissue consists of cells embedded in an extracellular matrix that binds them together. For example, muscle cells allow us to move, and nervous tissue sends electrical signals from one part of the body to another.
Each cell type has a distinct structure and purpose, but all are essential for life and overall health. Understanding how these cells work together helps us understand how diseases occur and develop treatments to prevent or cure them.

Human Body Cell Types Illustration (Copyright: Adam Jones)
Immune System Cell Types
Immune system cells are specialized cells that protect the body from infection and disease. They come in many forms, each with its own unique function. White blood cells like lymphocytes, monocytes, and neutrophils find and kill pathogens that are trying to get in. Other immune system cells include B cells that produce antibodies to fight off bacteria and viruses and T cells that attack infected cells and prevent them from reproducing.
Supporting a healthy immune system is crucial in keeping disease at bay. Healthy lifestyle habits such as eating a balanced diet, exercising regularly, and getting enough sleep are essential for maintaining a robust immune system. Additionally, Vitamin D, probiotics, and elderberry supplements can further support the body's natural defenses. Also, staying away from processed foods, limiting alcohol consumption, and avoiding smoking are all good habits to help keep your immune system in top shape.

Immune System Cells Illustration (Copyright: Adam Jones)
Stem Cells
Human stem cells are undifferentiated cells that have the potential to develop into specialized cells and tissues in the body. They can divide and multiply to form more stem cells or differentiate into various types of cells, such as muscle, bone, blood, and nerve cells. There are two main types of human stem cells: embryonic stem cells and adult stem cells.
Stem cells are produced in our body during early development and throughout our lifetime to help repair and regenerate damaged tissues. During embryonic development, stem cells divide and differentiate to form the various tissues and organs in the body. In adulthood, stem cells are present in various tissues and organs, mainly remaining quiescent until activated by injury or disease. These cells are found throughout the body, with the highest concentrations in bone marrow, brain, and skin. Hematopoietic stem cells in the bone marrow give rise to red blood cells, white blood cells, and platelets, while neural stem cells in the brain give rise to neurons and glial cells.
Stem cells have unique properties, making them a promising tool for fighting cancer. Due to their ability to differentiate into various types of cells, they can be used to replace damaged cells in cancer patients after chemotherapy and radiation therapy. This has led to stem cell therapies, such as bone marrow transplants, which help rebuild the immune system after cancer treatment. Moreover, stem cells can be used to deliver therapeutic agents directly to cancer cells. Researchers are studying how to manipulate stem cells to seek out and destroy cancer cells, a process known as targeted therapy. This approach could potentially eliminate cancer cells without harming healthy cells, which is often a side effect of traditional cancer treatments.

Stem Cells Illustration (Copyright: Adam Jones)
Section 2 - Unlocking the Secrets of the Human Genome
The Human Genome Project
The Human Genome Project (HGP) is a scientific endeavor that was launched in 1990. Its goal was to map the entire human genome, providing scientists with the necessary information and data to understand better and treat genetic diseases. Since its inception, this project has become one of the most significant achievements in modern science, unlocking new possibilities for medical treatments and personalized medicine.
A greater understanding of medicine was made possible after the Human Genome Project was completed in 2003. The most recent high-throughput DNA sequencing techniques are opening up intriguing new prospects in biomedicine. Outside of the original goal of genome sequencing, which was implemented, new fields and technologies in science and medicine have emerged. Precision medicine aims to combine the appropriate patients with the appropriate medicines. Precision medicine means using genetics and other methods to find the disease at a higher level of detail. The goal is to treat diseased subsets more accurately with new medicines.
The Human Genome Project has been hailed as a crucial turning point in the development of science. In the early days of the Human Genome Project, the human genome sequence was often called the "blueprint" of humanity or the complete instructions for making a human body that could be downloaded from the Internet. On the other hand, the project that started as an example of a genetic way of thinking ended up calling into question the validity of the overly simple genetic view of life by showing how many different biological systems there are. Human genome sequencing made the framework for the current biomedical study possible. Recent developments in DNA Sequencing have made it possible to generate data that goes far beyond what Sanger sequencing was designed to generate. As we move forward in the genomic era we are in now, "Next-Generation" Genome Sequencing is helping us learn a lot more about health and illness.
Genome Sequencing Saliva Collection
Saliva collection for genome sequencing is a straightforward process where the patient spits into a tube and sends it to the laboratory for analysis. This method is safe and painless, as there are no needles involved. Saliva provides an easy way to collect samples from patients with large numbers of genetic data points, making it ideal for use in genetics research and Personalized Medicine (PM).
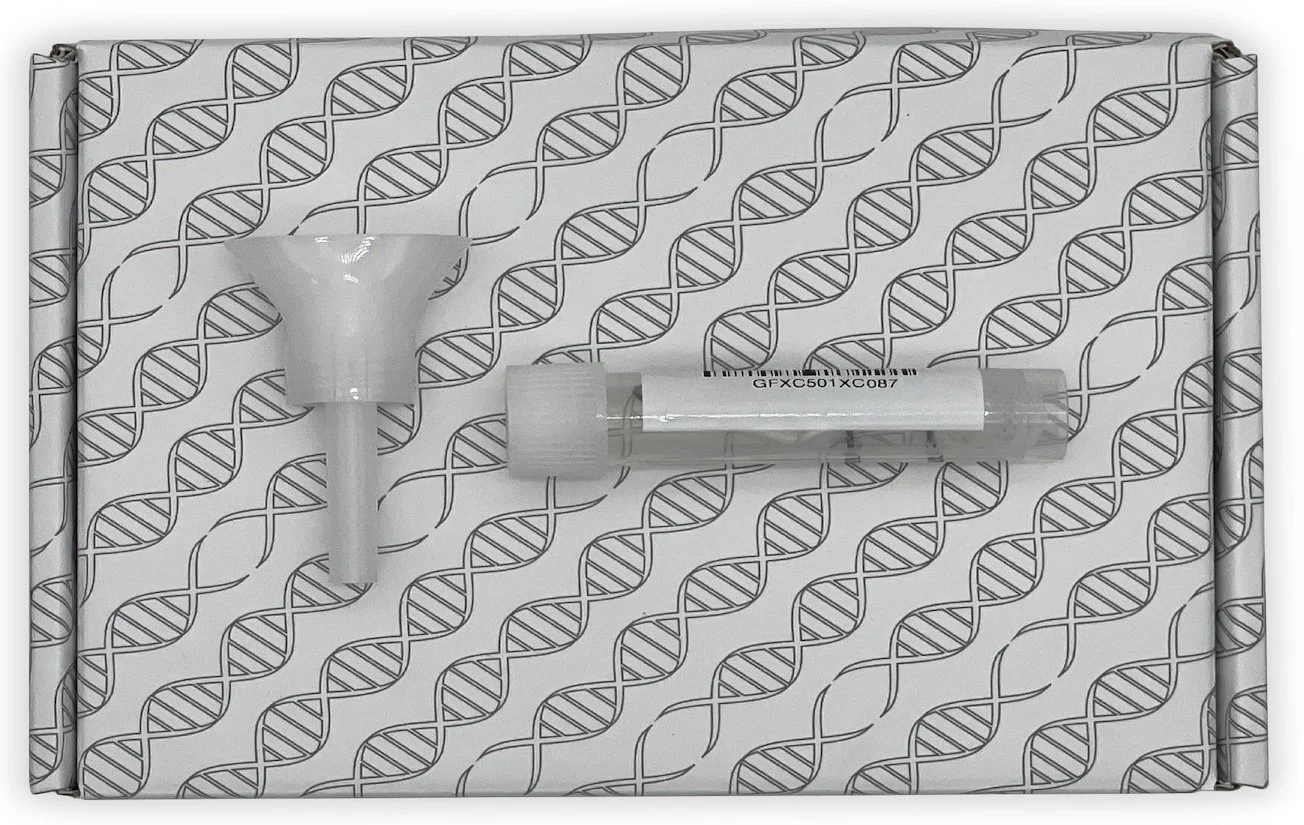
Genome Sequencing Saliva Collection Illustration (Copyright: Adam Jones)
Five Steps Process of Whole Genome Sequencing
DNA Extraction: Scientists take bacterial cells and extract their DNA by using a chemical technique called lysis. Lysis breaks apart the cell walls and releases its DNA, which is then purified.
DNA Shearing: DNA is cut into short fragments using mechanical forces or enzymes.
DNA Library Preparation: Scientists make many copies of the DNA fragments and add labels to them to be tracked during sequencing.
DNA Library Sequencing: The DNA library is loaded into sequencing machines that read each DNA fragment and produce a digital signal.
DNA Sequence Analysis: The sequencer produces millions of short DNA sequences, which are then analyzed by computers to determine the order of the nucleotides that make up a person’s genome.

Whole Genome Sequencing Process Illustration (Copyright: Adam Jones)
Additional Details In The Whole Genome Sequencing Process
The extended process for Whole Genome Sequencing, Whole Exome Sequencing, and Targeted Sequencing is much more complex. In addition to the five steps above, scientists must select the suitable sequencing method and technology, optimize environment conditions for DNA storage, use data analysis software, and interpret results. The advancement of medical technology brings about new possibilities for personalized medicine with an array of genomic tools currently being used in healthcare, such as Sequencing panels (Sanger and Next-Generation Sequencing) and Molecular Diagnostics.
Whole Genome Sequencing is a technique that allows for sequencing an entire human genome in a single experiment. It can provide information on genetic variations like Single Nucleotide Polymorphisms (SNPs), Copy Number Variations (CNVs), gene expression, and structural variations. Whole Genome Sequencing is used to identify the genetic basis of diseases, discover new treatments, and enable personalized healthcare.
Whole Genome Sequencing can provide increased accuracy in diagnosis and treatment by providing detailed information on a patient’s genetics, which can be compared to the known genetic sequences of healthy individuals. This comparison allows for the detection of genetic variations, which can be used to identify diseases or predispositions to certain illnesses. Additionally, Whole Genome Sequencing can provide information on gene expression and epigenetic modifications, allowing for a more detailed understanding of the molecular pathways involved in disease pathogenesis.
By utilizing Whole Genome Sequencing technology, clinicians can better understand their patients' diseases and create more specific treatments tailored to their needs. As Whole Genome Sequencing technology continues to be developed and refined, its use in healthcare will become increasingly common, allowing us to further explore the possibilities of personalized medicine.

Whole Genome Sequencing Process - Detailed Illustration (Copyright: Adam Jones)
Section 3 - Disease and Autoimmune Overview
Diseases and autoimmune conditions are often challenging to diagnose and manage due to their complex nature involving a multitude of factors. The human body is a complex system, and these conditions disrupt its intricate balance, leading to various symptoms and ailments. Traditional diagnostic methods often involve symptomatic analysis and medical history, which, while effective, may not always provide a comprehensive picture of the individual's health status.
In recent years, genomic sequencing has emerged as a potent tool in the medical field, providing deeper insights into the underlying genetic factors influencing health and disease. This technology allows for accurate and early detection of genetic predispositions towards certain diseases, enabling preventative measures to be taken before onset. In cases where diseases have already manifested, genomic sequencing can guide precision medicine, tailoring treatments to the individual's unique genetic makeup, thereby enhancing effectiveness and minimizing potential side effects.
Diseases
Cancer is a disease caused by abnormal cell growth. It can affect any body part, from the skin to the bones. Cancer occurs when normal cells in the body start growing and multiplying uncontrollably, damaging healthy tissue and forming tumors. Cancer cells can sometimes spread to other body parts through lymph or blood vessels.
There are many different types of cancer, depending on where it occurs in the body and what type of cells it affects. The most common types include breast cancer, prostate cancer, lung cancer, colorectal cancer, skin cancer, and leukemia. Each type has its own set of risk factors and symptoms that can help doctors diagnose it correctly.
Healthy and Unhealthy Cells
Cell health has a direct impact on our overall health and well-being. This is because healthy cells can fulfill their designated tasks, while unhealthy cells can lead to diseases and impair normal body functions.
This is called a disease when viruses, bacteria, and environmental toxins damage or change the body's cells. These damages result in changes in cell function, which can lead to cancer, Alzheimer’s disease, and other ailments.

Healthy and Unhealthy Cells Illustration (Copyright: Adam Jones)
Healthy and Cancerous Cells
This illustration offers a visual comparison of healthy and cancerous cells. Healthy cells contain DNA, which is made up of coding sequences that direct how cells interact with each other. When these coding sequences change, they can cause cells to function and divide in strange ways, leading to cancer growth. Cancer cells don't usually have the same structure as healthy cells, and they can grow and divide out of control, leading to tumors.

Healthy and Cancerous Cells Illustration (Copyright: Adam Jones)
Process of Cancer Development
Cancer is a complex set of diseases involving transforming normal cells into tumor cells. This process involves multiple steps, including genetic and epigenetic alterations, regular cell behavior changes, and environmental interactions. Understanding how cancer develops can help identify potential prevention and treatment targets.
The first step in cancer development is genetic alteration, which can be caused by external factors such as chemical carcinogens or radiation. Internal genetic mutations, such as those associated with inherited syndromes, can also contribute to cancer. These mutations cause changes in gene expression that lead to aberrant cell growth and proliferation.
Epigenetic changes are also an essential part of cancer development. Epigenetics refers to changes in gene expression without changing the underlying DNA sequence. These changes can occur due to environmental factors such as diet, lifestyle, or exposure to certain chemicals or radiation. They can also be caused by internal mechanisms such as aging or epigenetic inheritance from parents.
Once genetic and epigenetic changes have occurred, tumor cells start to form and interact with their environment. This interaction allows tumors to grow and spread through the body by invading healthy tissues or metastasizing to distant organs via the bloodstream or lymphatic system. The invasion process involves multiple steps, including adhesion, migration, invasion, and angiogenesis (formation of new blood vessels).
Cancer is a complex disease set that develops through a multi-step process involving genetics, epigenetics, and environmental interaction. Identifying critical steps in this process can provide insight into potential targets for preventive measures and treatments to stop this deadly disease's progression.

Process of Cancer Development Illustration (Copyright: Adam Jones)
Cell-Tissue Cancer Types
Common cell-tissue cancers include (but are not limited to) carcinomas, sarcomas, myelomas, leukemias, lymphomas, and mixed types.
Carcinomas are cancers that start in the skin or tissues that line organs like the lungs and stomach. Sarcomas begin in connective tissue such as muscles, fat, bones, cartilage, or blood vessels. Myelomas are cancers of the bone marrow, and leukemias involve white blood cells. Lymphomas affect the lymphatic system, which is a network of organs and tissues that removes harmful substances. Mixed types include more than one type of cell-tissue cancer and are often harder to treat.
Understanding how different types of cells work together in our bodies is essential to preventing diseases and developing treatment strategies.

Cell-Tissue Cancer Types Illustration (Copyright: Adam Jones)
Cancer Risk Factors
Cancer is an illness caused by the uncontrolled growth of abnormal cells in the body. Several risk factors can increase an individual's chances of developing cancer, including smoking, excessive alcohol consumption, exposure to certain chemicals or radiation, and genetics and/or environmental factors. While it is impossible to avoid all risk factors for cancer altogether, knowing what these risks are and how they interact with each other can help inform prevention strategies that individuals can take to reduce their likelihood of developing cancer.
Smoking is one of the most significant risk factors for various cancers, including lung, head, and neck cancers. Smoking affects the growth and spread of cancer cells due to certain chemicals in cigarette smoke, which bind with DNA molecules and cause them to mutate. These mutations lead to genetic alterations that can trigger abnormal cell growth and cancer development.
Excessive alcohol consumption also increases a person’s risk for certain types of cancers, such as colorectal cancer and breast cancer, by damaging healthy cells and causing genetic mutations that promote tumor formation.
Environmental carcinogens, such as arsenic or radiation, are also associated with a heightened risk of developing certain types of cancers, including skin and lung cancers. Some studies have found that prolonged exposure to even low levels of these substances significantly increases the likelihood of tumors forming in exposed individuals.
In addition to environmental exposures, inherited genetic mutations increase an individual’s susceptibility to developing cancer later in life. Some inherited gene abnormalities make people more prone to developing hereditary forms of particular kinds of cancers, such as ovarian or prostate cancer, at a younger age than average.
Understanding the different risk factors associated with an increased chance for cancer development and progression can help individuals be better informed about how they should modify their lifestyle habits to reduce their potential for getting sick from these deadly diseases.

Cancer Risk Factors Illustration (Copyright: Adam Jones)
Autoimmune Diseases and How They Develop
Autoimmune diseases occur when the body's immune system mistakenly attacks healthy cells. This abnormal response can lead to a wide range of diseases, including Rheumatoid Arthritis, Lupus, and Type 1 Diabetes, to name a few. The exact cause of autoimmune diseases is unknown, but genetic, environmental, and hormonal factors are thought to play a role. In these diseases, the body produces autoantibodies that attack normal cells as if they were foreign invaders, resulting in inflammation and tissue damage. The development of autoimmune diseases is a complex process involving a loss of immune tolerance and a failure of regulatory mechanisms that usually keep the immune response in check.
Mast Cells | Normal Role, Allergies, Anaphylaxis, MCAS and Mastocytosis
Mast cells are a crucial part of the immune system, with a primary role in allergic reactions and fight against parasites. They are filled with granules containing histamine and other chemicals. In response to an allergen, mast cells release these chemicals, causing an immediate inflammatory reaction. However, in conditions such as allergies, anaphylaxis, Mast Cell Activation Syndrome (MCAS), and Mastocytosis, mast cells can overreact, leading to symptoms varying from mild discomfort to life-threatening reactions. In anaphylaxis, mast cells release a large amount of histamine, causing a severe allergic reaction. MCAS is a condition where mast cells inappropriately release these chemicals, leading to chronic symptoms. In Mastocytosis, there is an abnormal proliferation of mast cells, often in the skin or bone marrow, which results in various symptoms, including skin lesions, abdominal pain, and bone pain. Understanding these conditions can help in the development of treatments to moderate mast cell activity.
Section 4 - Oxford Nanopore MinION Whole Human Genome Sequencing
Oxford Nanopore
The Oxford Nanopore MinION and MinION-Mk1C are trailblazers in the genomics arena with their capacity to sequence the entire human genome. Their standout features are their compact size and portability. The MinION, for example, is comparable in size to a USB stick, allowing it to be effortlessly connected to a laptop for instantaneous, high-throughput DNA/RNA sequencing.
At the heart of these devices lies the indispensable Flow Cell or Flongle. Essentially, these are flow cells replete with hundreds of nanopore channels that facilitate the movement of individual DNA or RNA strands. As each molecule navigates through the nanopore, it generates an electrical signal. This signal is then captured and scrutinized to deduce the nucleotide sequence.
Before the sequencing process can begin, a vital Library Preparation Process is undertaken. This step consists of fragmenting the genomic DNA, attaching adapters to the fragment ends, and loading these prepared fragments onto the flow cell. These adapters function as guides, leading the DNA strands into the nanopores.
A significant benefit of this technology is its ability to produce long-read sequences. This feature proves particularly advantageous for whole genome sequencing as it can help tackle complex regions typically difficult to handle with short-read technologies. The sequencing data is delivered in a FAST5 file format - a hierarchical format based on the HDF5 file format.
Accompanying the MinION devices is the user-friendly MinKNOW software. It streamlines the sequencing process by enabling real-time basecalling, guiding users through the sequencing run steps, and providing dynamic read tracking and quality feedback.
Upon completion of the sequencing, the data can be uploaded to the AWS Cloud. This feature offers convenient data storage and access and facilitates additional bioinformatics analyses.
The Oxford Nanopore MinION Mk1B and MinION-Mk1C provide a comprehensive, portable solution for whole human genome sequencing. By harnessing the power of nanopore technology, they deliver long-read sequencing capable of resolving complex genomic regions while simultaneously offering real-time data and cloud-based analysis capabilities.
The Benefits of Nanopore Technology
Nanopore technology provides significant flexibility and scalability in the field of sequencing. It allows for sequencing of any read length, including ultra-long, and aids in easier genome assembly, resolving structural variants, repeats, and phasing. Its scalability ranges from portable to ultra-high-throughput sequencing, and the technology is consistent across all devices. It offers direct sequencing of native DNA or RNA, thereby eliminating amplification bias and identifying base modifications. The process comprises streamlined library preparation with a rapid 10-minute DNA library prep and high DNA and RNA yields from low input amounts. Further, it allows for real-time analysis, providing immediate access to results and the ability to enrich regions of interest without additional sample prep. The technology also supports on-demand sequencing, removing the need for sample batching and providing flexibility in throughput.
How Nanopore Sequencing Works
Nanopore sequencing stands at the forefront of technological innovation, offering direct, real-time analysis of DNA or RNA fragments of any length. This groundbreaking technology operates by monitoring shifts in an electrical current as nucleic acids journey through a nanopore - a hole on the nanometer scale. This resulting signal is subsequently decoded to reveal the precise DNA or RNA sequence.
The beauty of this technology lies in the user's ability to manipulate fragment length through their selected library preparation protocol. This flexibility allows for the generation of any desired read length, ranging from short to ultra-long sequences. A specialized enzyme motor governs the translocation or movement of the DNA or RNA strand through the nanopore.
Once the DNA or RNA fragment has successfully traversed the nanopore, the motor protein disengages, freeing the nanopore for the next incoming fragment, due to the presence of an electrically resistant membrane, all current is compelled to pass through the nanopore, which guarantees a clear and unequivocal signal.

How Nanopore Sequencing Works Illustration (Ref 1)
Oxford Nanopore MinION Mk1B and MinION Mk1C Sequencers
The Oxford Nanopore MinION Mk1B and MinION Mk1C Sequencers are pushing the boundaries in genomic research with their exceptional DNA and RNA sequencing performance. These devices distinguish themselves with a compelling blend of affordability, compactness, and real-time data streaming capabilities.
Their real-time data streaming feature offers researchers an unprecedented opportunity to witness the sequencing process in action, enabling immediate analysis of the data. The MinION stands out for its impressive capacity to potentially generate up to 48 gigabases (Gb) of data from a single flow cell in 72 hours. This high-throughput data generation significantly enhances the accuracy and depth of genomic investigations.
Moreover, these devices incorporate sequencing and analysis software, removing the need for separate bioinformatics tools and efficiently converting raw data into meaningful insights. The MinION Mk1B and MinION Mk1C Sequencers epitomize the perfect union of convenience, power, and adaptability, solidifying their position as indispensable assets in contemporary genomics research.
Oxford Nanopore MinION Mk1B
The Oxford Nanopore MinION Mk1B Sequencer is heralding a new era in genomic research, thanks mainly to its highly affordable price point, starting at just USD 1,000. This initial cost is significantly lower compared to traditional sequencing platforms. Additionally, the expenses associated with consumables and reagents needed for the sequencing process are quite reasonable, ensuring modest upkeep costs. This cost structure positions the MinION Mk1B as an incredibly cost-effective option for both large-scale laboratories and smaller academic research endeavors.
A standout feature of the MinION Mk1B Sequencer is its capability to link directly to a standard laptop for data processing. This substantially diminishes the need for expensive, specialized computing infrastructure that is typically a prerequisite in genomic research. The sequencing data is processed in real-time on the linked laptop using the proprietary software provided by Oxford Nanopore Technologies. This software efficiently manages all necessary procedures, including base calling, alignment, and variant detection. Utilizing a laptop for processing not only simplifies the setup but also enhances the overall cost-effectiveness and portability of the device. This proves to be a substantial benefit for field-based studies and research on the move.

Oxford Nanopore MinION Mk1B Illustration (Ref 2)
Oxford Nanopore MinION Mk1C
The MinION Mk1C Sequencer, akin to its sibling, the MinION Mk1B, boasts a highly competitive price tag, with an initial cost starting at a reasonable USD 4,900. This budget-friendly pricing extends to the necessary consumables and reagents for sequencing, ensuring that maintenance costs stay within manageable limits.
A distinguishing feature of the MinION Mk1C Sequencer is its built-in GPU-powered unit, a trailblazer in the genomics arena. This robust feature empowers the device to tackle computationally intensive tasks right on the sequencer itself, bypassing the need for costly, specialized computing infrastructure.
The sequencer comes equipped with Oxford Nanopore Technologies' proprietary software, which oversees the real-time processing of sequencing data. It efficiently handles all critical processes, from base calling and alignment to variant detection. The inclusion of this built-in GPU not only streamlines the setup but also significantly enhances the device's cost-effectiveness and portability. As such, it's an indispensable resource in contemporary genomics research.

Oxford Nanopore MinION Mk1C Illustration (Ref 3)
Oxford Nanopore Flow Cell with 512 Channels and Flongle with 126 Channels
The Oxford Nanopore MinION Mk1B and MinION Mk1C Sequencers are engineered to effortlessly integrate with the Oxford Nanopore Flow Cell, which is equipped with 512 channels. This compatibility empowers researchers to fully leverage these devices, optimizing throughput for their sequencing data. Each channel is capable of processing an individual DNA or RNA molecule, facilitating parallel processing of hundreds of samples at once. This high-capacity processing accelerates sequencing, delivering faster results and enabling real-time data analysis. Moreover, the Flow Cell's reusable feature enhances the cost-effectiveness of the sequencing process as it can be rinsed and reused for multiple runs.
For projects on a smaller scale or initial test runs, the MinION Mk1B and Mk1C Sequencers can alternatively employ the Flongle – an adapter for the Flow Cell that offers 126 channels. While the Flongle provides lower throughput than the full Flow Cell, it serves as a more budget-friendly option for researchers managing limited samples or funds without sacrificing the quality of the sequencing data. The Flongle represents a cost-effective gateway into nanopore sequencing, encouraging more frequent experimentation and quicker research design iteration.
In both cases, whether utilizing the full Flow Cell or the Flongle, the MinION Mk1B and Mk1C Sequencers continue to democratize genomic research. They adapt to various research scales and budgets, making sophisticated genomic sequencing accessible to all.

Oxford Nanopore Flow Cell with 512 Channels and Flongle with 126 Channels Illustration (Ref 4)
Library Preparation for Oxford Nanopore MinION Mk1B and MinION Mk1C Sequencers
The library preparation procedure utilizing Oxford Nanopore Technology for the MinION Mk1B and MinION Mk1C devices is both simple and proficient. It commences with extracting high-purity DNA or RNA from your selected sample. The quality and volume of the resulting nucleic acids are then assessed using methods such as spectrophotometry or fluorometry.
Once the nucleic acid quality is affirmed, they are readied for sequencing. This step involves ligating sequencing adapters to the DNA or RNA fragments. These adapters, often called sequencing 'leaders,' are the key elements the sequencing motor attaches to, allowing the nucleic acids to traverse through the nanopore.
If your research zeroes in on specific genomic regions or transcripts, you can choose to conduct target enrichment at this stage. This process involves designing probes that will bind with the desired sequences, facilitating their isolation and enrichment.
Upon completing adapter ligation (and target enrichment, if applied), the prepared library is loaded onto the flow cell of the MinION Mk1B or MinION Mk1C device. The flow cell hosts thousands of nanopores, each capable of sequencing individual DNA or RNA molecules in real time.
Once the flow cell is primed, the device is connected to a computer, and the sequencing run is launched using Oxford Nanopore Technologies' software. The sequencing process possesses the flexibility to be paused and resumed as necessary, enabling sequencing on demand.
The generated sequence data can be analyzed either in real-time or post-run, contingent on computational capabilities and project objectives. The software avails tools for base calling, alignment, and variant detection, providing a holistic overview of the obtained genomic data.

Oxford Nanopore Library Preparation Kits Illustration (Ref 5)
Oxford Nanopore Automated Multiplexed Amplification and Library Preparation
The Oxford Nanopore VolTRAX emerges as a groundbreaking addition to the sequencing arena, boasting advanced features crafted explicitly for multiplexed amplification, quantification, and the preparation of sequencing libraries from biological samples. With its superior capabilities, VolTRAX guarantees uniform library quality even in non-laboratory settings, democratizing genomic research.
This compact, USB-powered gadget utilizes VolTRAX cartridges to streamline laboratory procedures preceding nanopore sequencing. This automation drastically decreases the need for manual intervention, thus minimizing human error and enhancing reproducibility. The ability of VolTRAX to operate standalone, without the need for an internet connection, further magnifies its attractiveness for field-based genomic studies or in areas with restricted connectivity.
The VolTRAX operates by directing droplets across a grid, following a course preset by software. This autonomous approach to library preparation means you provide your reagents and sample, select your preferred program, and the device handles the rest of the library preparation. Depending on the chosen protocol, reagents are transported, combined, separated, and incubated as needed. Upon completing the VolTRAX operation, the prepared library is conveniently located under the extraction port, ready to be pipetted directly onto your nanopore sequencing flow cell.
Yet, the functionalities of VolTRAX stretch beyond mere library preparation. Users can explore additional functions such as DNA extraction and performing incubations at varied temperatures.

Oxford Nanopore Automated Multiplexed Amplification and Library Preparation Illustration (Ref 6)
Oxford Nanopore Automated Sample-to-Sequence Devices
Oxford Nanopore is at the forefront of innovation with its development of TurBOT and TraxION - automated sample-to-sequence devices set to transform the realm of genomics. These trailblazing devices are designed to automate the entire sequencing workflow, from sample extraction to data interpretation. Once the sample is loaded, the device takes over, handling DNA or RNA extraction, library preparation, sequencing, base calling, and data analysis — all without human intervention. This degree of automation minimizes the chance of human error, boosts productivity, and quickens turnaround times, enhancing the overall efficacy of genomic analyses.
The TurBOT and TraxION devices deliver consistent sequencing library preparation by automating extraction and library preparation, a crucial factor for achieving reliable, high-quality sequencing results. The feature of automated sequencing ensures a continuous, unbroken stream of data, enabling real-time genome analysis. Furthermore, thanks to a built-in base calling feature, these devices can convert raw signals into readable sequence data instantly, reducing post-processing needs and improving the pace of data acquisition and analysis.
In the sphere of human genome sequencing, the automation provided by TurBOT and TraxION could have a profound impact. These devices are set to render human genome sequencing a swift, routine, and cost-effective process, broadening its accessibility and application in both research and clinical environments. Automating data analysis also paves the way for real-time identification of genetic variations, which could prove particularly advantageous in fields like personalized medicine and genetic disease diagnosis.

Oxford Nanopore Automated Sample-to-Sequence Devices Illustration (Ref 7)
Oxford Nanopore MinKNOW and EPI2ME Analysis Software
Oxford Nanopore's MinKNOW software sits at the heart of the nanopore sequencing experience, deftly handling data acquisition, real-time analysis, and feedback. As a bridge between users and Oxford Nanopore devices, MinKNOW orchestrates sequencing and data acquisition while offering real-time feedback and base calling. This pioneering software is instrumental in ensuring the precision of sequencing data by rapidly detecting and correcting potential issues that could compromise the quality of the sequencing run, thereby securing the generation of dependable genetic data.
Working harmoniously with MinKNOW, Oxford Nanopore's EPI2ME emerges as a user-friendly and robust platform for post-sequencing data analysis. EPI2ME furnishes preconfigured workflows tailored for an extensive range of applications, granting users the versatility to fine-tune analyses according to their specific needs. The platform encompasses workflows for Human Genomics, Cancer Genomics, Genome Assembly, Metagenomics, Single-Cell and Transcriptomics, Infectious Diseases, Target Sequencing, and more, ensuring that EPI2ME meets the demands of a wide array of research disciplines.
Notably, the intuitive design of EPI2ME makes it a formidable yet accessible tool for researchers. This user-centric platform demystifies the often intricate process of genomic data analysis, enabling even beginners to traverse the data and easily interpret the results. With EPI2ME, Oxford Nanopore has democratized genomic data analysis, equipping researchers with an effective tool to derive valuable insights from their nanopore sequencing data.
Oxford Nanopore Additional Sequencers (GridION and PromethION)
The Oxford Nanopore family boasts formidable additions with the GridION and PromethION Sequencers, which build upon the benefits of the compact, cost-effective MinION devices. The MinION's scalability, affordability, and mobility have been pivotal in introducing nanopore sequencing to numerous laboratories worldwide. Yet, for expansive projects or when higher throughput is necessary, the GridION and PromethION emerge as robust alternatives.
The GridION system is a sleek benchtop device that can accommodate up to five flow cells, enabling several DNA or RNA sequencing experiments to operate simultaneously. Its capability to generate up to 240 Gb of high-throughput data per run positions it as the go-to choice for labs, necessitating greater capacity without a substantial increase in space or cost. Its flexibility in handling varying sample sizes while preserving sequencing efficiency highlights its attractiveness to researchers in pursuit of an equilibrium between throughput and expenditure.
At the other end of the spectrum, the PromethION offers an unparalleled level of sequencing prowess with its ability to house 1 - 48 flow cells. This remarkable capacity facilitates flexible, on-demand sequencing, rendering it the preferred device for large-scale genome sequencing initiatives. With data yields reaching up to 13.3 Tb per run, the PromethION is uniquely prepared to cater to a broad array of high-throughput applications, spanning from single-cell genomics to population-scale sequencing. The PromethION's adaptability in terms of the number of flow cells, coupled with its outstanding output, paves the way for a new era of large-scale, high-throughput sequencing endeavors.

Oxford Nanopore Additional Sequencers (GridION and PromethION) Illustration (Ref 8)
Final Human Genome Sequenced Data Save, Upload, and Next Steps
The process of Human Genome Sequencing generates data in the FAST5 file format, a structured data format engineered to house scientific data. This adaptable format is proficient in storing raw nanopore signals, base-called sequences, and quality scores, among other data types. Once the sequencing run concludes on the Oxford Nanopore device, the FAST5 files are automatically stored on the local computer linked to the device. These files are typically arranged in a directory structure that categorizes the data by the sequencing run, facilitating easy data management and retrieval.
After the local storage of FAST5 files, they can be transferred to a cloud environment such as AWS for storage and advanced analysis. This process generally involves setting up an S3 bucket in the AWS Management Console, which functions as an Object Storage Service. It's an ideal solution for storing substantial amounts of unstructured data like the FAST5 files. The local FAST5 files can be uploaded to the S3 bucket using the AWS Command Line Interface (CLI) or via the AWS Management Console.
For AWS HealthOmics, a HIPAA-compliant service custom-built for healthcare and life science customers, the FAST5 files can be securely uploaded and stored while adhering to regulatory standards. AWS HealthOmics services also provide tools for genomic data analysis, interpretation, and secure collaboration, making it an all-in-one platform for researchers dealing with human genomic data. The upload process mirrors that of S3 but incorporates additional security measures to safeguard data privacy and integrity.
Section 5 - Human Genome Sequencing Data with AWS HealthOmics
Before the advent of Amazon HealthOmics, developing cloud-based genomics systems required a manual integration of various Amazon AWS products. For instance, one might have manually combined services such as Amazon S3 for scalable storage, Amazon EC2 for flexible compute capacity, and Amazon RDS for a managed relational database service. Additionally, Amazon Athena could have been employed for interactive query services and Amazon QuickSight for business analytics. This manual assembly of diverse AWS products would have provided the necessary infrastructure for a genomics system similar to Amazon HealthOmics.
However, having to integrate these services manually was not only time-consuming but also required extensive technical expertise. It also led to data fragmentation, with various omics data scattered across multiple databases. This made it challenging to manage, analyze, and derive actionable insights from the data efficiently.
Amazon HealthOmics significantly simplifies the process of managing and analyzing omics data by consolidating various services into a centralized solution. This unified platform not only saves significant time and resources but also enhances the capability to manage and analyze data effectively. It presents managed pipelines that adhere to AWS's best data management and governance practices, thereby eliminating the need for users to oversee these procedures themselves and allowing them to dedicate their attention exclusively to analytics.
In addition to storing, analyzing, and querying omics data, HealthOmics boasts variant stores compatible with VCFs and genome VCFs to facilitate variant data storage. It also incorporates annotation stores that support TSVs, CSVs, annotated VCFs, and GFF files, streamlining the variant normalization procedure.
By unifying various omics data under a single platform, researchers can gain comprehensive insights more efficiently, accelerating the pace of scientific discovery and improving patient outcomes. Furthermore, the HealthOmics system is purposefully engineered to simplify and scale clinical genomics. Its user-friendly and efficient approach empowers users to focus on scientific research, precision medicine, and innovation.
How AWS HealthOmics Works
Amazon HealthOmics is a powerful tool designed for storing, querying, and analyzing various omics data like genomics and transcriptomics, including DNA and RNA sequence data. The platform provides a comprehensive solution for large-scale analysis and collaborative research.

How AWS HealthOmics Works Illustration (Ref 9)
The process begins with the input of omics sequence data into the HealthOmics system. This data can include RNA or DNA sequences and other types of omics data.
Next, this data is stored in the Sequence Store, a feature of Amazon HealthOmics designed to support large-scale analysis and collaborative research. The Sequence Store accommodates the vast amount of data inherent in omics research, providing a centralized and secure location for data storage.
Once the data is stored, the Bioinformatics Workflow comes into play. This automated system provisions and scales infrastructure as needed, simplifying the process of running your analysis. It eliminates the need for manual intervention, ensuring efficient and streamlined data processing.
Alongside sequence data, the platform also manages Variant and Annotation Data. It optimizes this data for easy access and analysis, helping researchers to identify patterns and trends more effectively.
Moreover, Amazon HealthOmics can handle Clinical and Medical Imaging Data. This allows for a more holistic view of a patient's health, integrating genetic information with clinical observations and imaging data.
Finally, it facilitates Multimodal and Multiomic Analysis. Users can query and analyze data from multiple sources, generating new insights and contributing to a deeper understanding of complex biological systems.
Amazon HealthOmics provides a comprehensive, streamlined, and user-friendly platform for managing and analyzing a wide range of omics data, promoting collaboration, and facilitating new discoveries in Healthcare and Life Sciences.
How The Children's Hospital of Philadelphia (CHOP) is Utilizing AWS HealthOmics

Children’s Hospital of Philadelphia (CHOP) Logo (Ref 10)
The Children's Hospital of Philadelphia (CHOP), a pioneer in pediatric care in the US, treats over 1.4 million outpatient visits and inpatient admissions annually. CHOP is renowned for groundbreaking innovations in gene therapies, cell therapies, and treatments for rare diseases via the CHOP Research Institute. To enhance its data-driven approach to personalized medicine, CHOP has leveraged AWS HealthOmics to manage, query, and analyze its extensive and diverse omics data, including genomic and transcriptomic data.
CHOP launched the Arcus initiative in 2017, a suite of tools and services that synergize biological, clinical, research, and environmental data to improve patient outcomes. Within this initiative, the Arcus Omics library was developed, a collection of over 12,000 exome-genome datasets leading the hospital's omics and big data strategies. However, scaling this system and eliminating data silos posed significant challenges.
The solution came in the form of AWS HealthOmics, a secure and efficient platform for large-scale data analytics. It allows all data to be stored in a single database, simplifying the process of querying data and saving considerable time when searching for specific genes. This facilitates better diagnosis and treatment while enabling bioinformatics engineers to concentrate on child health issues.
This improved accessibility has led to faster diagnoses, better treatments, and improved patient outcomes. Patient privacy is maintained through HIPAA-eligible AWS services, strict security controls, and an AWS HIPAA Business Associate Agreement. As a testament to the system's efficacy, CHOP researchers have made significant discoveries, such as identifying a genetic mutation in epilepsy patients.
AWS HealthOmics has been transformational for CHOP, enabling the hospital to analyze multiomic data effectively and yield actionable insights. By offloading the complexities of infrastructure management to AWS, the hospital can focus on accelerating diagnoses and crafting targeted treatments. The platform's integration capabilities and stringent security controls foster a secure environment for data-driven discoveries in pediatric healthcare. AWS HealthOmics proves to be the backbone of CHOP's personalized medicine approach, unlocking the potential for substantial advancements in pediatric healthcare.
Creating a More Holistic View of the Patient

Creating a More Holistic View of the Patient Illustration (Ref 11)
AWS HealthOmics leverages the power of multi-omics data, including the genome, transcriptome, metabolome, epigenome, microbiome, and proteome, to advance preventative and precision medicine.
Multi-Omics Data
Genome: The genome, an organism's comprehensive set of DNA encompassing all its genes, is a blueprint for building and maintaining that organism. In humans, this complex structure comprises 23 chromosome pairs, hosting an estimated 20,000-25,000 genes. Leveraging this genome data in platforms like AWS HealthOmics facilitates the detection of genetic variants potentially causing disease or influencing therapeutic responses. This critical information not only aids in predicting disease risk but also paves the way for the creation of personalized treatments.
Transcriptome: The transcriptome, a comprehensive set of RNA transcripts generated by the genome in a specific cell or under certain conditions, encompasses various types of RNA molecules, including messenger RNA (mRNA), transfer RNA (tRNA), and ribosomal RNA (rRNA). The study of this transcriptome, termed transcriptomics, sheds light on gene expression and its influencing factors. Furthermore, transcriptome data enables a deeper understanding of gene expression and regulation patterns, providing critical insights into disease stages and progression. This knowledge aids in customizing treatments to align with the specific stage and progression of the disease.
Metabolome: The metabolome encompasses the entire array of small-molecule chemicals present within a biological entity like a cell, tissue, or organism under specific conditions. These molecules, end products of cellular activities, furnish a real-time snapshot of an organism's physiological state. The study of this vast chemical landscape, known as metabolomics, elucidates metabolic pathways and reveals how genetic factors and environmental conditions influence them. This metabolome data not only enables the prediction of disease onset and progression but also facilitates the evaluation of treatment responses.
Epigenome: The epigenome constitutes a record of chemical modifications to an organism's DNA and histone proteins, which, while not altering the DNA sequence, can be inherited by subsequent generations. These modifications, referred to as epigenetic marks, play a significant role in influencing gene expression and contributing to phenotypic diversity. The study of these changes, known as epigenomics, is vital for comprehending complex biological processes and diseases. Furthermore, epigenome data provides insights into heritable changes that affect gene expression. It sheds light on the role of environmental factors in disease development and progression, thereby enabling the development of more precise preventative strategies.
Microbiome: The microbiome represents the entire community of microorganisms, including bacteria, fungi, and viruses, that reside within a specific environment, notably the human body. These microbial communities profoundly impact various aspects of host health, such as immune function, digestion, and nutrient absorption. The examination of this microbiome, an area of study known as microbiomics, unravels intricate interactions between host organisms and their resident microbes. Additionally, microbiome data offers insights into the role of microbiota in disease onset, progression, and treatment response, thereby enhancing our understanding of these complex interactions.
Proteome: The proteome embodies the entire collection of proteins that can be or is expressed by a genome, cell, tissue, or organism at any given moment. This entity is far more intricate than the genome, considering a single gene can encode multiple proteins due to phenomena like alternative splicing and post-translational modifications. The study of this complex protein landscape, referred to as proteomics, offers invaluable insights into cellular functions and processes, given that proteins serve as the functional units of the cell. Additionally, proteome data discloses protein abundances and modifications, serving as a direct indicator of cellular activity and disease states. This vital information aids in the identification of disease biomarkers and the formulation of targeted therapies.
Multi-Modal Data
Electronic Health Records (EHRs) offer a comprehensive patient history, allowing healthcare providers to make informed decisions, reduce medical errors, and customize treatment plans. Claims data can reveal patterns of healthcare service utilization, providing insights for predicting future health events and managing population health. Clinical Notes/Audio are rich sources of unstructured data that, when harnessed effectively, can unearth valuable clinical insights to enhance patient outcomes.
Vaccination records are integral to a patient's health narrative, informing immune responses and potential vulnerability to diseases. Social and geographical data offer invaluable insights into the socio-economic and environmental factors influencing health, aiding in developing tailored preventive strategies and interventions. Devices and instruments yield real-time physiological data, enabling ongoing patient monitoring and early detection of health aberrations.
Through advanced analysis techniques, Digital Pathology and Radiology Imaging can identify subtle changes in tissue samples or imaging scans that may indicate disease, facilitating early diagnosis and treatment.
Each data type, individually and collectively, empowers AWS HealthOmics to create a holistic understanding of a patient's health, leading to more accurate diagnoses, effective treatments, and improved patient outcomes.
Multi-Omics and Multi-Modal for Effective Cancer Treatment Approach by Drug Response Data Modeling
Multi-Omics and Multi-Modal data approaches are crucial in creating a comprehensive and effective cancer treatment plan. This process includes several stages, beginning with data collection. This stage involves collecting multi-omics data from patient samples, such as genomics, proteomics, and metabolomics, in addition to multi-modal data from various imaging modalities like MRI and PET scans. These data sets provide a detailed molecular and morphological landscape of the patient's cancer.
The next stage involves data integration, a crucial step to combine and harmonize these heterogeneous data types into a unified view. This is followed by data analysis, where advanced bioinformatics and Machine Learning algorithms are employed to decipher complex patterns and relationships in this integrated data. Treatment modeling comes in next, where the insights from data analysis are utilized to develop a predictive model for drug response. This model can predict how a patient's cancer is likely to respond to various drugs based on their unique multi-omics and multi-modal data. Model evaluation is then carried out to assess the performance and reliability of the predictive model. Finally, the treatment selection stage involves applying the model predictions to clinical practice, aiding oncologists in selecting the most effective treatment strategy for each individual patient.
1) Data Collection: First, compile all relevant data from various sources. For the Multi-Omics data, this means gathering information from the patient's genome, transcriptome, metabolome, epigenome, microbiome, and proteome. Similarly, Multi-Modal data entails the collection of Electronic Health Records, Claims, Clinical Notes, Vaccinations, Social & Geographical Data, Devices & Instruments data, Digital Pathology records, and Radiology Imagery.
# Example command to load data
omics_data = load_omics_data(patient_id)
modal_data = load_modal_data(patient_id)
2) Data Integration: Next, integrate the collected data to create a comprehensive and cohesive view of the patient's health status. This allows for a better understanding of the cancer's characteristics and potential treatments.
# Example command to integrate data
integrated_data = integrate_data(omics_data, modal_data)
3) Data Analysis: Analyze the integrated data, aiming to identify patterns and correlations that could influence the success of different treatment strategies.
# Example command for data analysis
analysis_results = analyze_data(integrated_data)
4) Treatment Modeling: Based on the data analysis, develop models to predict the patient's response to various drugs. This involves Machine Learning algorithms that can process complex and diverse data to generate accurate predictions.
# Example command to model drug response
drug_response_model = model_drug_response(analysis_results)
5) Model Evaluation: Evaluate the performance of the models using various metrics to ensure their accuracy and reliability.
# Example command to evaluate model
model_evaluation = evaluate_model(drug_response_model)
6) Treatment Selection: Lastly, based on the model's results, select the most promising treatment strategy for the cancer patient.
# Example command to select treatment
selected_treatment = select_treatment(model_evaluation)
Please note that the commands mentioned earlier serve as hypothetical examples and are purely illustrative. The precise commands you'll use will vary significantly based on factors such as the programming language you're working with, the structure of your data, and the specific analysis and modeling techniques you are implementing.
AWS HealthOmics Automated Genomics Storage and Analysis Introduction
In the detailed two-part series, AWS delves into the innovative AWS HealthOmics. This solution is tailor-made to address the complexity of storing and processing biological data in healthcare and life science industries. Amazon Omics equips bioinformaticians, researchers, and scientists with a secure platform to store, process, and analyze their data, transforming raw genomic sequence information into valuable insights.
Furthermore, AWS explains how AWSHealthOmics can be integrated with AWS Step Functions to automate the conversion of raw sequence data into actionable insights. This includes showcasing a reference architecture, complete with sample code, providing a streamlined workflow for efficient genomics data storage and analysis.

Automated End-to-End Genomics Data Storage and Analysis Using AWS HealthOmics Illustration (Ref 12)
AWS HealthOmics Documentation
AWS HealthOmics Videos
Transform Genomic and Biological Data Into Insights with AWS HealthOmics (2:10)
Transform Omics Data Into Insights with AWS HealthOmics Video (38:56)
Section 6 - Use Cases and Resources for Amazon Bedrock in Healthcare
As we navigate the precision medicine landscape, tools like AWS HealthOmics and Amazon Bedrock stand out as pivotal assets in healthcare. In Section 6, we will delve deeper into the multifaceted applications and resources of AWS Bedrock within the healthcare sphere, underscoring how its potent features and capabilities can transform the industry. We'll illustrate how AWS Bedrock can be utilized for patient data processing, medical research, and more, demonstrating its potential to revolutionize healthcare delivery.
From handling vast amounts of health data to executing intricate algorithms for predictive modeling, the potential of AWS Bedrock is vast. This section will further spotlight resources that can aid users in maximizing this technology, offering a comprehensive guide for those keen to explore the crossroads of technology and healthcare.
Brief Explanation of Foundation Models (FMs), Large Language Models (LLMs), and Generative AI
Foundation Models, Large Language Models, and Generative AI each encompass distinctive elements within the expansive landscape of Artificial Intelligence, characterized by their unique features and applications.
Foundation Models are essentially AI models pre-trained on extensive data sets that can be fine-tuned for specific tasks or fields. Their designation as "Foundation" Models stems from their role as a base structure upon which more specialized models can be constructed. An example of a Foundation Model is GPT by OpenAI, which has been trained on a broad spectrum of internet text, enabling it to generate text that mirrors human language based on the input it receives.
Large Language Models represent a subcategory of Foundation Models specifically engineered to comprehend and generate human language. Trained on copious amounts of text data, they can produce coherent sentences that are contextually appropriate. In other words, while all Large Language Models are Foundation Models, the reverse is not necessarily true. Notable examples of Large Language Models include OpenAI's GPT and Google's BERT.
Generative AI constitutes a branch of Artificial Intelligence encompassing models capable of generating new content, whether text, images, music or any other form of media. Both Foundation Models and Large Language Models fall under the umbrella of Generative AI when utilized to generate new content. However, Generative AI also incorporates different model types, such as Generative Adversarial Networks (GANs) that can produce images or models capable of creating music.
In essence, Foundation Models lay the foundational groundwork for AI models; Large Language Models employ this foundation to precisely understand and generate language, while Generative AI refers to any AI model capable of producing new content.
Foundation Models (FMs), Large Language Models (LLMs), and Generative AI in Precision Medicines and Treatment
Foundation Models are designed to learn from substantial datasets encompassing a wide range of patient data, including genomic, transcriptomic, and other omics information. These models form a foundational layer for creating more specialized models. For instance, if a patient's genomic profile reveals a genetic variant linked to a specific cancer type, a Foundation Model can detect this correlation and propose treatments known to be effective against that variant.
On the other hand, Large Language Models are a subset of Foundation Models with a specific focus on processing and generating human language. Within precision medicine, Large Language Models can sift through medical literature, results from clinical trials, and patient health records to formulate personalized treatment suggestions. For instance, by integrating a patient's health history with cutting-edge medical research, a Large Language Model can pinpoint the most suitable targeted therapy tailored to the patient's unique cancer type and genetic composition.
Generative AI, encompassing Large Language Models, offers the ability to generate novel data based on the information it has been trained on. Within the realm of cancer treatment, this capability allows Generative AI to model potential responses of various genetic variants to different therapies, thereby bolstering drug discovery and development efforts.
In addition to their role in personalized treatment, these AI models are critical in broadening our understanding of medicine and treatment development. By discerning patterns across extensive datasets, they can unearth new knowledge on how different genetic variants react to distinct treatments, thereby propelling advancements in the rapidly evolving field of precision oncology.
AWS Bedrock
AWS Bedrock is a fully integrated service that facilitates access to robust Foundation Models from premier AI companies via an API. It equips developers with tools to personalize these models, thereby simplifying the process of crafting applications that harness the power of AI. The service provides a private customization feature for Foundation Models using your data, ensuring you retain control over its usage and encryption.
Compared with OpenAI API, AWS Bedrock presents similar functionality but with a broader array of models. For instance, it offers the Anthropics Cloud model for text and chat applications, comparable to OpenAI's GPT model. For image-related tasks, it grants access to the Stable Diffusion XL model for image generation. This diverse selection of models and the ability to customize them with your data delivers a more bespoke and flexible strategy for utilizing AI across various applications.
It's important to clarify that AWS Bedrock is not an AI model itself but serves as a platform providing API access to other cutting-edge models. It enables you to commence with Foundation Models like AWS Titan and refine them using a dataset specific to an industry or topic. This methodology can yield a specialized Large Language Model capable of answering questions or generating text pertinent to that subject.
The utilization of an existing Foundation Model to develop Large Language Models offers numerous advantages. It conserves time and resources since there's no need to train a model from the ground up. You can tap into the extensive knowledge encapsulated by the Foundation Model and fine-tune it according to your specific requirements. This strategy can result in more precise and relevant outcomes than training a fresh model without prior knowledge.
Creating your own Foundation Model gives you more control over the model's learning trajectory and output. You can instruct the model to concentrate on certain data aspects or disregard others. This can result in a highly specialized and accurate model within its domain. Once armed with a Foundation Model, you can generate even more specialized Large Language Models, thereby offering custom solutions for specific tasks or industries.
Foundation Models and Large Language Models Creation Workflow
To harness the comprehensive genomic, transcriptomic, and other omics data from patients stored in AWS HealthOmics for the development of a Foundation Model or Large Language Model in AWS Bedrock, a series of systematic steps need to be undertaken. The end goal is to create tailored treatment plans, propelling the progress of precision medicine.
1) Data Compilation and Integration: The initial phase involves assembling and combining the necessary omics data from AWS HealthOmics. This encompasses genomic, transcriptomic, genetic variants, gene expression levels, and other pertinent patient data.
2) Data Preprocessing and Standardization: Once the data collection is complete, the next step is to preprocess and standardize the data to ensure its validity and compatibility. This may involve normalizing gene expression levels, annotating genetic variants, and rectifying any inconsistencies or errors.
3) Training of Foundation Model or Large Language Model: With the clean and standardized data in place, it can then be employed to train a Foundation Model or Large Language Model on AWS Bedrock. The model will be trained to recognize patterns within the omics data that are linked to specific diseases or health conditions.
4) Fine-Tuning and Validation of Model: Post the initial training phase, the Foundation Model or Large Language Model will undergo fine-tuning using a smaller, disease-specific dataset. The model's performance will then be validated using separate test data to confirm its accuracy in predicting health outcomes and recommending suitable treatments.
5) Generation of Tailored Treatment Recommendations: Once the model has been meticulously trained and validated, it can be used to produce tailored treatment recommendations. By analyzing a patient's omics data, the model can estimate their risk for certain diseases and suggest treatments designed for their unique genetic profile.
6) Ongoing Learning and Enhancement: Even post-deployment, the model continues to learn and improve as more patient data is collected and analyzed. This enables the model to be updated to incorporate new medical research insights.
These Foundation Models or Large Language Models can also serve broader applications besides individual patient treatment. They can identify common patterns across vast patient populations, offering valuable insights for epidemiological studies and public health initiatives. Additionally, they could facilitate drug discovery and development by predicting how various genetic variants might react to different treatments. In this way, AI models trained on omics data could play a crucial role in propelling personalized medicine and enhancing patient outcomes.
Pediatric Cancer Treatment Example
In a children's hospital, a young patient is admitted with a cancer diagnosis. The first step in their treatment journey involves collecting a saliva sample for genomic sequencing. This process provides an in-depth look at the patient's genetic composition, which is vital for identifying specific genetic variants that could influence the child's condition.
Following the completion of the genomic sequencing, the data is transferred into AWS Bedrock. This platform is designed for training and deploying bespoke Machine Learning models, including Foundation Models. Foundation Models are trained on comprehensive datasets encompassing genomic, transcriptomic, and other omics data from numerous patients, enabling them to pinpoint connections between particular genetic variants and specific cancers.
In this case, the Foundation Model trained on AWS Bedrock would examine the child's sequenced genome alongside AWS HealthOmics data, an exhaustive repository of health-related omics data. This examination would involve contrasting the child's genetic variants, gene expression levels, and other pertinent omics data with similar cases within the AWS HealthOmics database.
The Foundation Model could then discern this link and suggest treatments that have proven effective for similar variants in the past, creating a foundation for a personalized treatment plan.
Simultaneously, Large Language Models, another type of Foundation Model created to decode and generate human language, can augment the Foundation Models analysis. Large Language Models can scrutinize medical literature, clinical trial outcomes, and patient health records to formulate personalized treatment suggestions.
In this context, the Large Language Model trained on Amazon Bedrock could assess the most recent medical research related to the child's specific cancer type and genetic composition. It could also consider any supplementary information from the child's health record, such as past illnesses or treatments, allergies, etc.
By cross-referencing this extensive array of information, the Large Language Model could recommend the most potent targeted therapy for the child's specific cancer type and genetic composition, further refining the personalized treatment plan.
Hence, the combination of AWS Bedrock and AWS HealthOmics data equips medical professionals with the tools to devise a precision treatment plan tailored to the patient's genomic profile. This approach can potentially enhance the treatment's effectiveness and improve the patient's prognosis.
Autoimmune Disease Diagnosis and Treatment Example
In a medical setting, an adult patient arrives displaying a myriad of symptoms indicative of an autoimmune disorder, but diagnosing the specific disease proves difficult. The initial step involves obtaining a saliva sample from the patient for genomic sequencing. This process offers physicians an intricate snapshot of the patient's genetic profile, shedding light on any genetic variants that could be causing their health issues.
Upon completion of the genomic sequencing, the data is transferred into AWS Bedrock, a platform specifically engineered for training and deploying customized Machine Learning models. Foundation Models are then employed, having been trained on vast datasets comprising genomic, transcriptomic, and other omics data from a multitude of patients.
These Foundation Models scrutinize the patient's sequenced genome alongside AWS HealthOmics data, an exhaustive database of health-related omics data. By contrasting the patient's genetic variants, gene expression levels, and other pertinent omics data with similar cases within the HealthOmics database, the Foundation Models can pinpoint potential connections between specific genetic variants and certain autoimmune diseases.
In parallel, Large Language Models, another type of Foundation Model tailored to decode and generate human language, can supplement the Foundation Models analysis. Large Language Models can examine medical literature, clinical trial outcomes, and patient health records to formulate personalized treatment suggestions.
For this patient, the Large Language Model trained on AWS Bedrock could assess the most recent medical research related to the patient's unique genetic composition and potential autoimmune disease. It could also consider any supplementary information from the patient's health record, such as past illnesses or treatments, allergies, etc.
By cross-referencing this extensive array of information, the Large Language Model could recommend the most potent targeted therapy for the patient's specific genetic composition and potential autoimmune disease, further refining the personalized treatment plan.
Typically, diagnosing an autoimmune disease can take upwards of four years due to the complexity of these conditions and the overlapping symptoms among different diseases. However, amalgamating genomic sequencing, Machine Learning models like Foundation Models and Large Language Models, and comprehensive health databases like AWS HealthOmics can potentially expedite this process significantly.
These technologies can reveal insights that traditional diagnostic methods may overlook, leading to faster and more precise diagnoses. By facilitating precision medicine, they can also aid in crafting treatment plans tailored to the patient's unique genetic profile, potentially enhancing treatment results and improving the quality of life for patients with autoimmune diseases.
AWS Bedrock Documentation
AWS Bedrock Videos
This exceptional video illustrates how the application of Generative AI in healthcare can significantly enhance the speed and accuracy of care and diagnoses. It highlights the work of clinicians at the University of California San Diego Health who utilize Generative AI to examine hundreds of thousands of interventions, enabling them to identify those that yield positive effects on patients more rapidly.
By combining traditional Machine Learning predictive models with Amazon SageMaker and integrating Generative AI with large language models on AWS Bedrock, these clinicians can correlate comorbidities with other patient demographics. This innovative approach paves the way for improved patient outcomes.
Research Articles
Foundation Models for Generalist Medical Artificial Intelligence
How Foundation Models Can Advance AI in Healthcare from Stanford HAI
Stanford Data Ocean - Additional Biomedical Data Science Education Material
Stanford Data Ocean is a pioneering serverless platform dedicated to precision medicine education and research. It offers accessible learning modules designed by Stanford University's lecturers and researchers that simplify complex concepts, making precision medicine understandable for everyone. The educational journey begins with foundational modules in research ethics, programming, statistics, data visualization, and cloud computing, leading to advanced topics in precision medicine. Stanford Data Ocean aims to democratize education in precision medicine by providing an inclusive and user-friendly learning environment, equipping learners with the necessary tools and knowledge to delve into precision medicine, irrespective of their initial expertise level. This approach fosters a new generation of innovators and researchers in the field.

Stanford Data Ocean Illustration (Ref 13)
Section 7 - Final Thoughts
The invaluable role of Multi-Omics and Multi-Modal data integration becomes apparent when considering the comprehensive health insights it provides. This methodology amalgamates many data types, from genomics to proteomics, offering a complete view of biological systems that surpasses the limitations of single data-type analysis.
In personalized medicine, these strategies reveal intricate patterns and bolster accurate predictions about disease susceptibility, progression, and response to treatment. The Oxford Nanopore MinION, a revolutionary portable DNA/RNA sequencer, is at the forefront of this transformation. Its versatility and cost-effectiveness have made genomic studies accessible beyond advanced laboratories, democratizing genomics. The swift diagnosis times this technology enables are crucial in time-critical conditions.
AWS HealthOmics and AWS Bedrock are pivotal in efficiently managing Multi-Omics and Multi-Modal data. HealthOmics provides a unified repository that dismantles data silos and promotes seamless integration and analysis. Simultaneously, AWS Bedrock facilitates developing and implementing Machine Learning models, including Foundation Models and Large Language Models. These tools harness the power of AI in analyzing complex health data, yielding more profound insights and paving the way for genuinely personalized treatment strategies.
The advantages of this infrastructure are numerous and significant. It signifies a new era in medical research and treatment strategies, where all data is consolidated in one location, empowering researchers to probe deeper, derive more accurate conclusions, and, consequently, suggest more tailored treatments. This shift in paradigm fuels the vision of personalized medicine, marking a transformative stage in healthcare with the potential to enhance patient outcomes significantly.
References
(Ref 4) - Oxford Nanopore Flow Cell with 512 Channels and Flongle with 126 Channels
(Ref 6) - Oxford Nanopore Automated Multiplexed Amplification and Library Preparation
(Ref 7) - Oxford Nanopore Automated Sample-to-Sequence Devices
(Ref 8) - Oxford Nanopore Additional Sequencers (GridION and PromethION)
(Ref 12) - Automated End-to-End Genomics Data Storage and Analysis Using AWS HealthOmics